【Python爬虫】Scrapy模块爬取微信公众号历史内容——抓包篇
【Python爬虫】Scrapy模块爬取微信公众号历史内容——数据分析篇
【Python爬虫】Scrapy模块爬取微信公众号历史内容——Python实战篇
【Python爬虫】Scrapy模块爬取微信公众号历史内容——数据导出篇
首先下载Fiddler并设置https捕抓
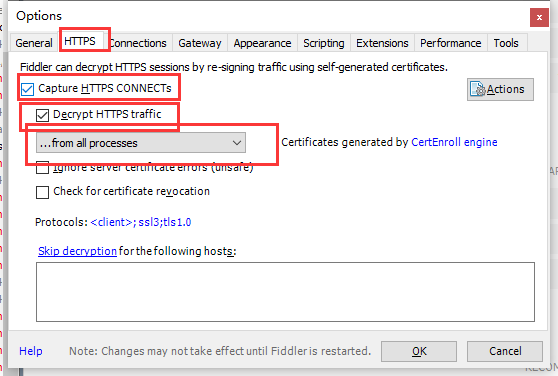
设置方法打开fd点击Tools->Options->HTTPS
勾选选项出现弹窗选择yes或者是如图
打开微信公众号
打开微信公众号历史记录后滑动页面到底部fd中会捕抓到一个https的请求双击它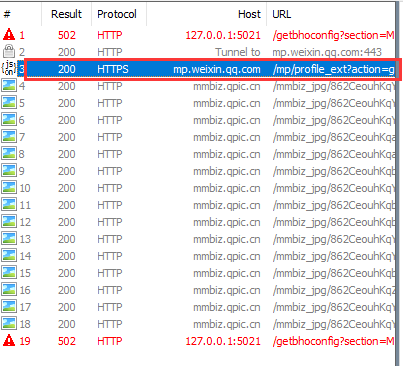
点击raw有一个链接可以直接点击浏览器打开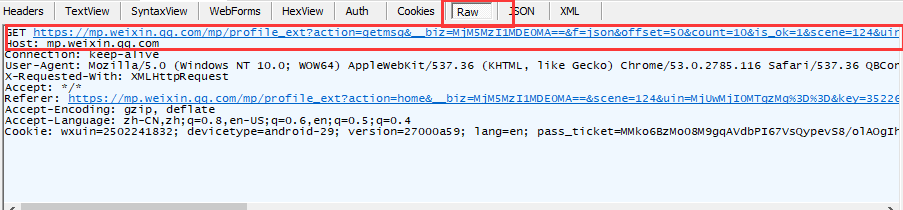
浏览器打开后是这样子的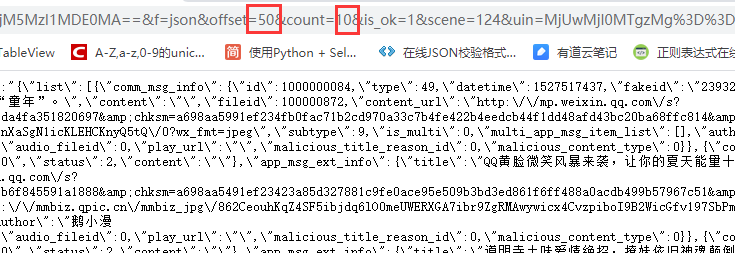
其中osffset是当前位置,count就是数量
开始offset为0后以10递增count10就代表每次获取十条数目
开始用Python编程爬虫
创建scrapy工程 scrapy startproject projectnameSpider
创建scrapy爬虫文件scrapy genspider projectname 公众号域名
用Pycharm打开
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Jamie793’ S Blog!
 wechat
wechat alipay
alipay
评论