【Python爬虫】Scrapy模块爬取微信公众号历史内容——抓包篇
【Python爬虫】Scrapy模块爬取微信公众号历史内容——数据分析篇
【Python爬虫】Scrapy模块爬取微信公众号历史内容——Python实战篇
【Python爬虫】Scrapy模块爬取微信公众号历史内容——数据导出篇
前两章节中我们学习了如何抓包和分析数据这节我们将开始进行
Python实战打开Pycharm
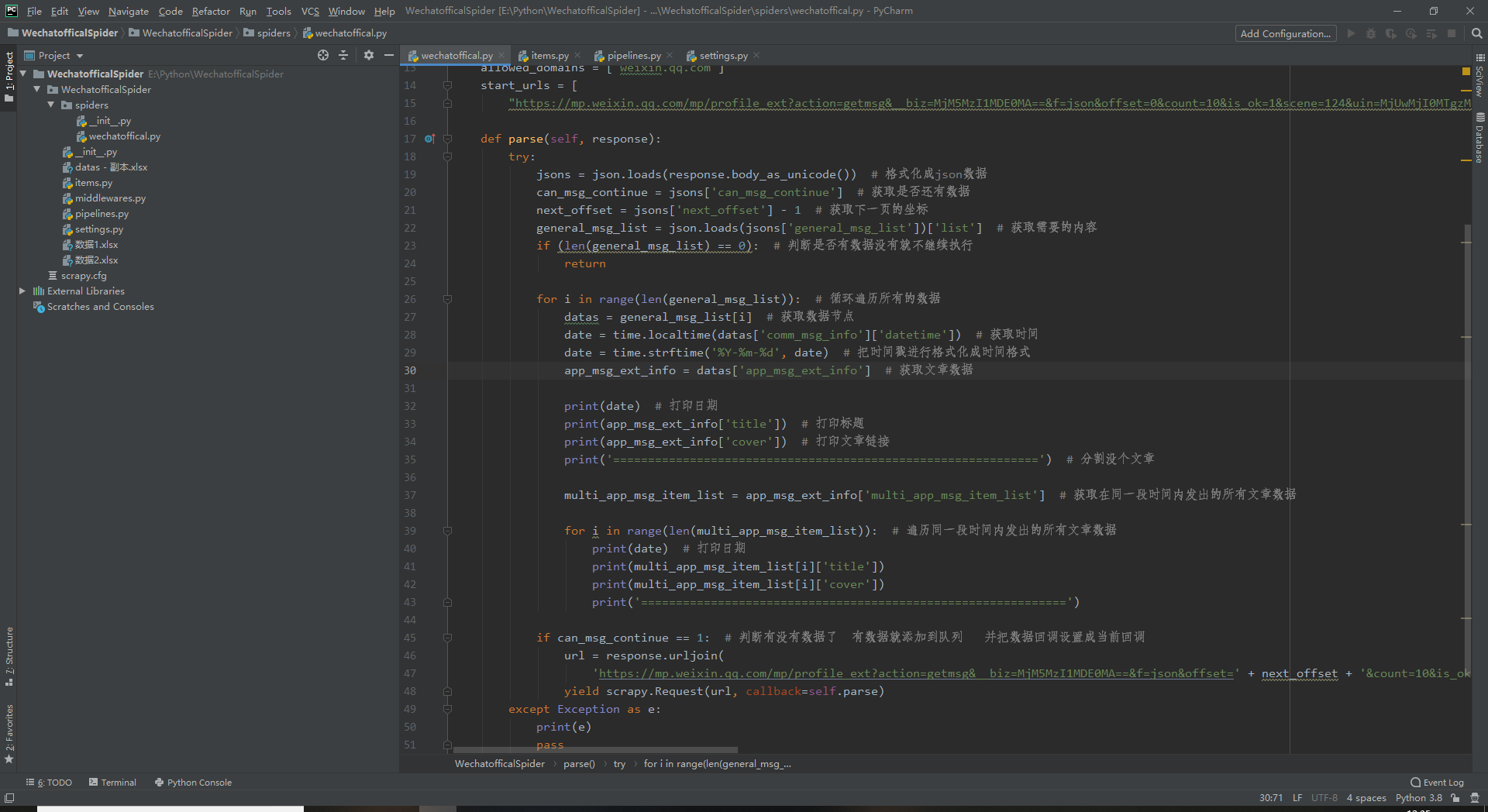
allowed_domains这个呢是只允许爬取在这个域名下的内容,填的是微信公众号的域名都一样的
start_urls这个就是我们前面提取出来的链接把链接的offset改为0就是从第一页开始爬起
parse这个函数是自动生成的
我们需要在这里编写爬虫回调
回调写完后
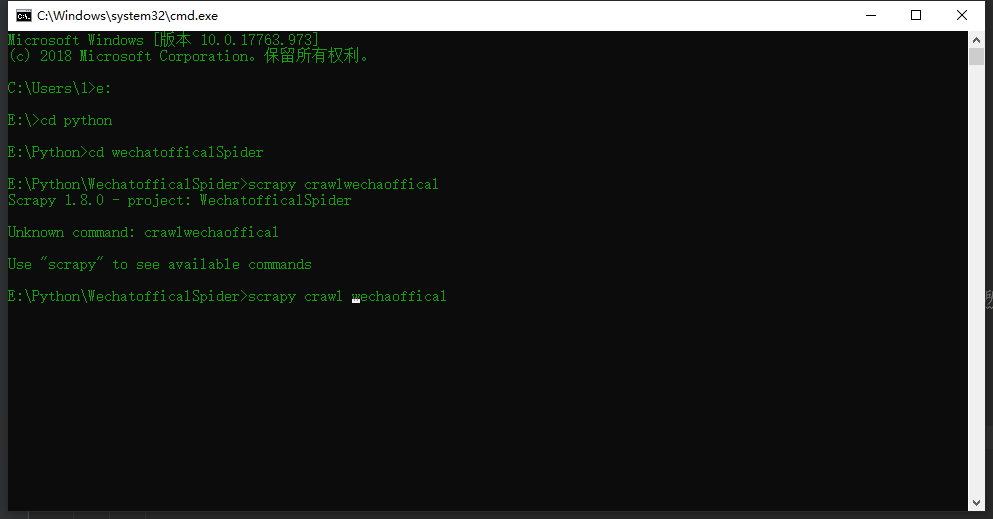
win+r打开运行输入cmd 输入你文件所在的盘符然后cd到你文件目录
如我是路径是e:pythonspio
先输入e:回车然后
cd pythonspio回车就行了
输入scrapy crawl name运行爬虫
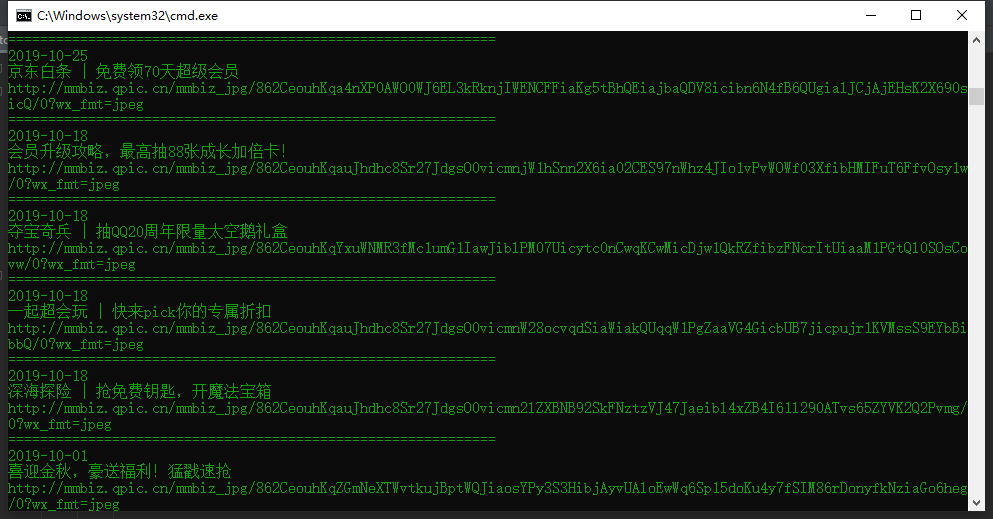
try包围是因为当key失效会报错
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Jamie793’ S Blog!
 wechat
wechat alipay
alipay
评论