【Python爬虫】Scrapy模块爬取微信公众号历史内容——抓包篇
【Python爬虫】Scrapy模块爬取微信公众号历史内容——数据分析篇
【Python爬虫】Scrapy模块爬取微信公众号历史内容——Python实战篇
【Python爬虫】Scrapy模块爬取微信公众号历史内容——数据导出篇
打开后打开setting文件把ROBOTSTXT_OBEY设置成True
DOWNLOAD_DELAY = 0.5 这里是每次发送包后的延迟如图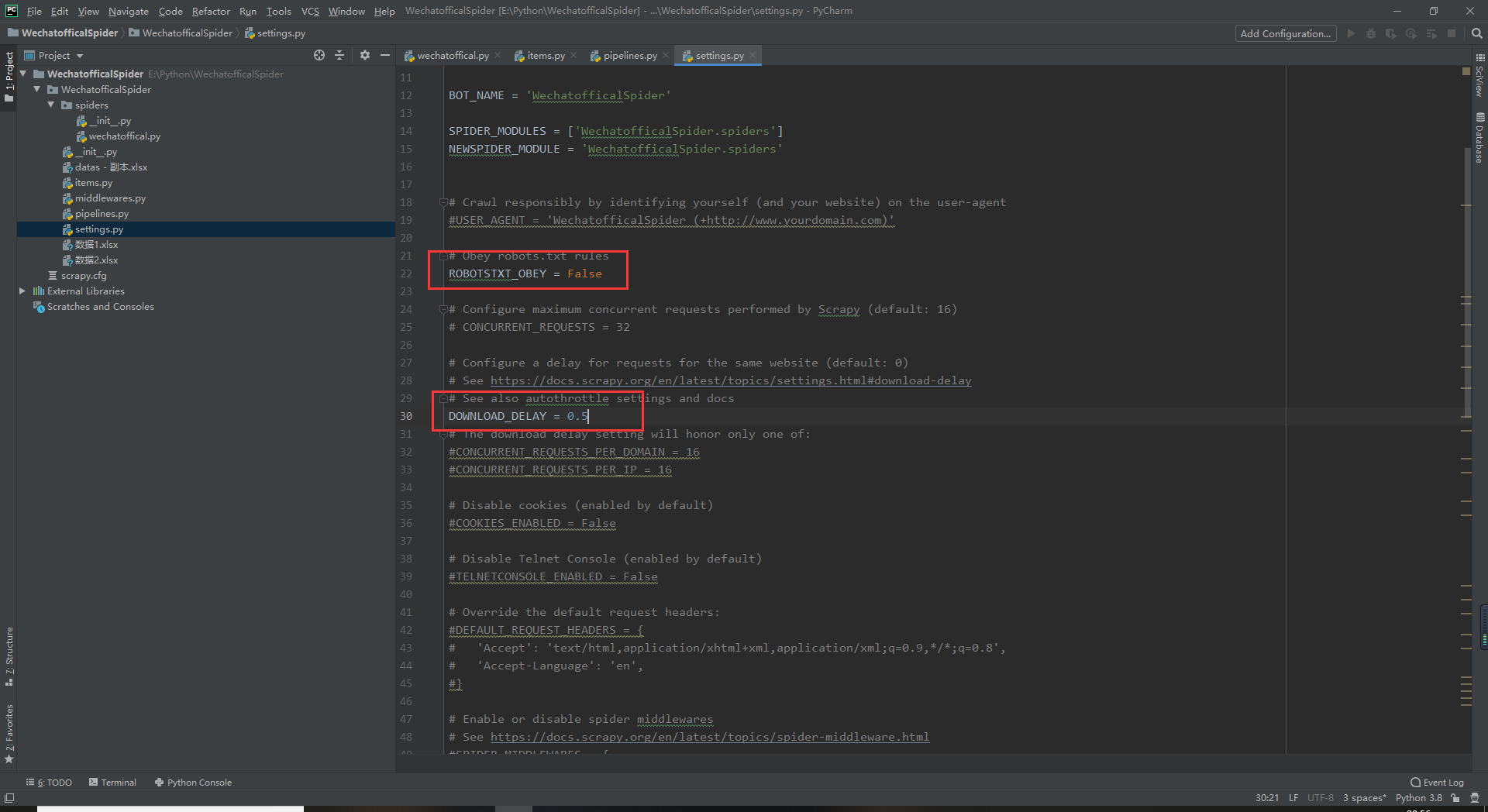
然后我们对上个文章中获取到的链接进行分析这里我用火狐浏览器因为火狐浏览器自带了格式化json数据的功能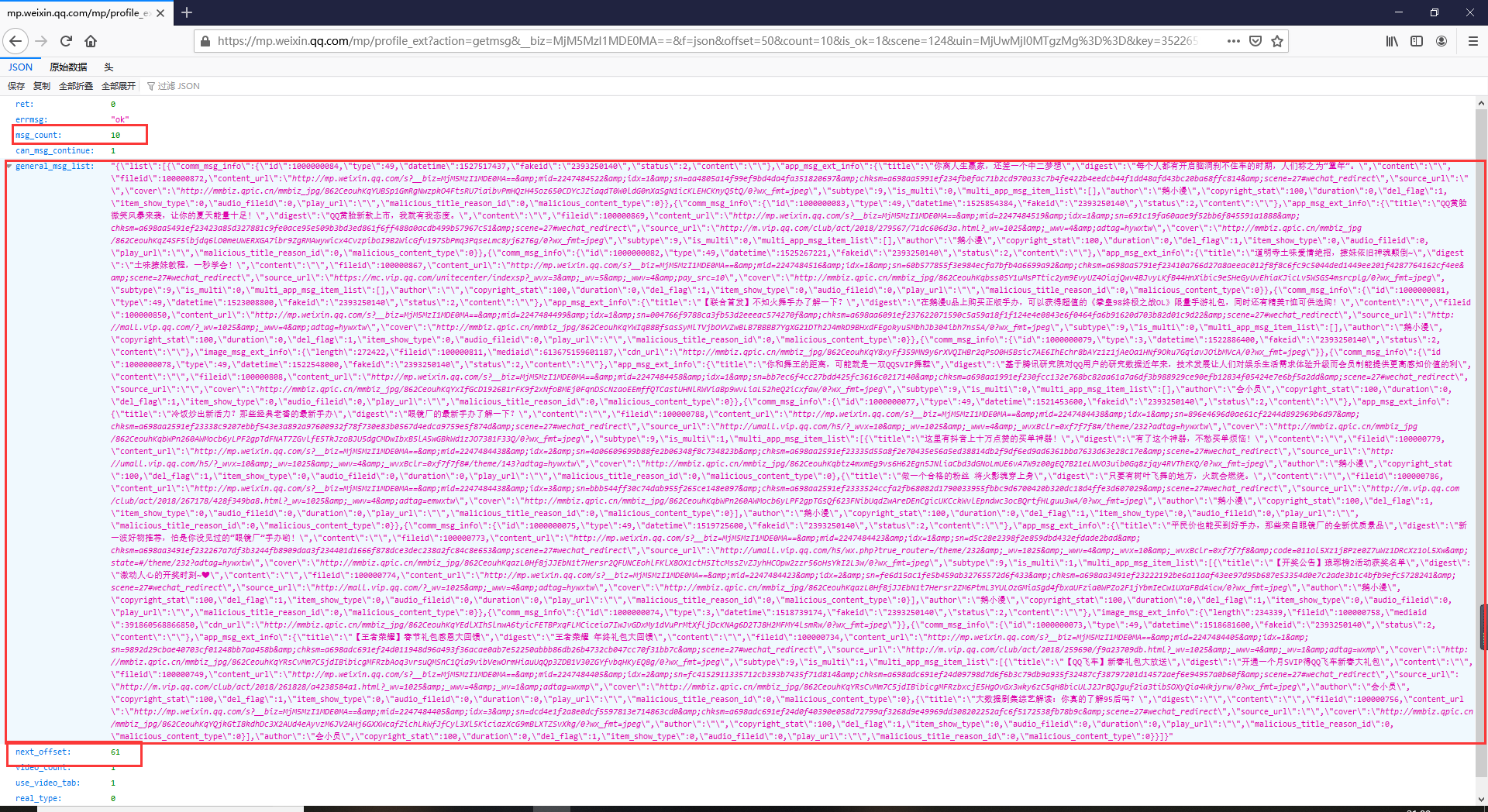
can_msg_continue这个为1就是还有数据为0则没有数据了
msg_count数据的条数
next_offset这个值-1就是得到下一个offset的值
general_msg_list是一个json数据我们需要对他进行格式化这也是我们最需要的数据
先用sublime text对这个数据的替换成空然后打开在线Json格式化
进行格式化分析
在把格式化的内容粘贴回sublime进行分析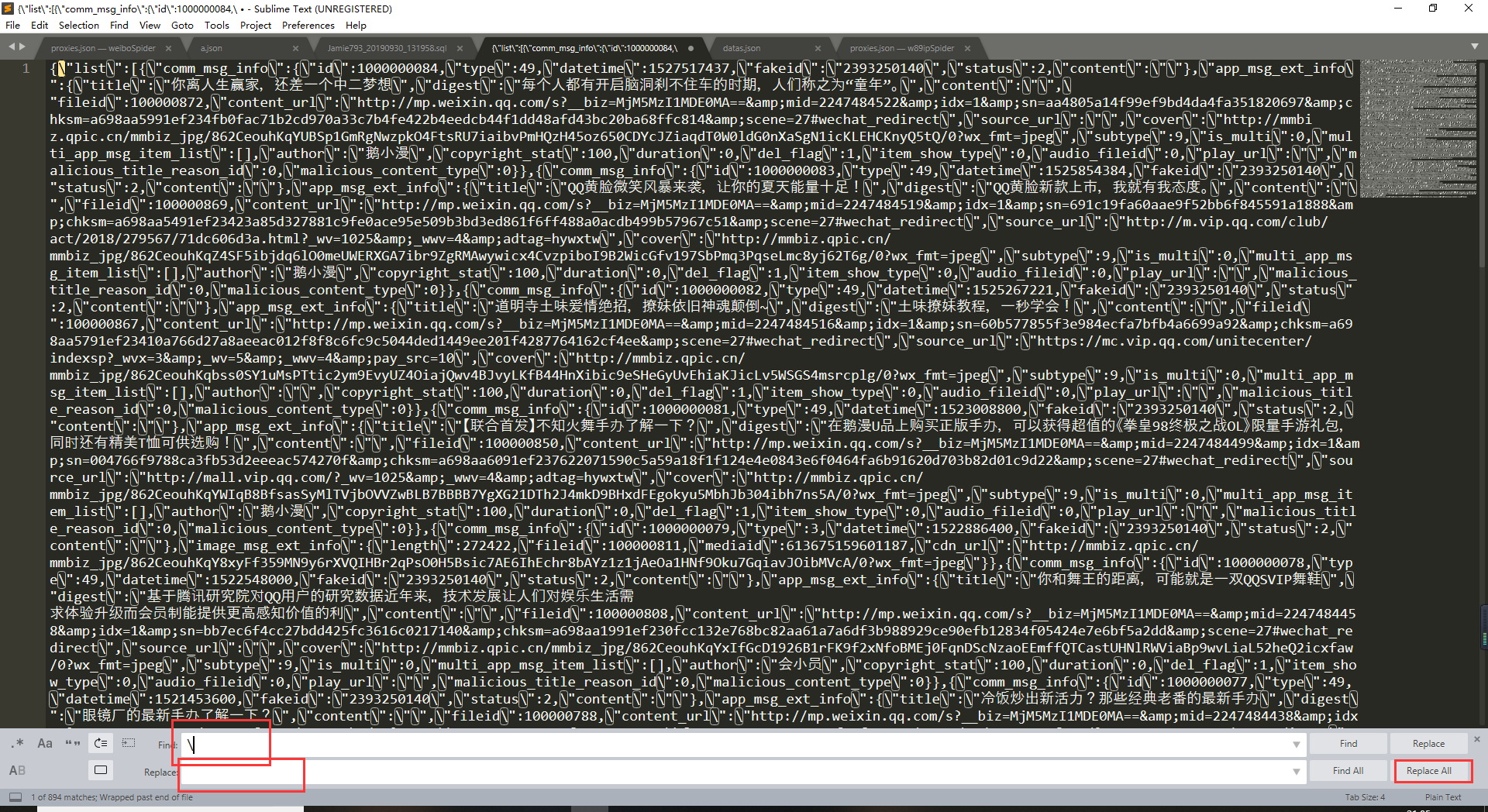
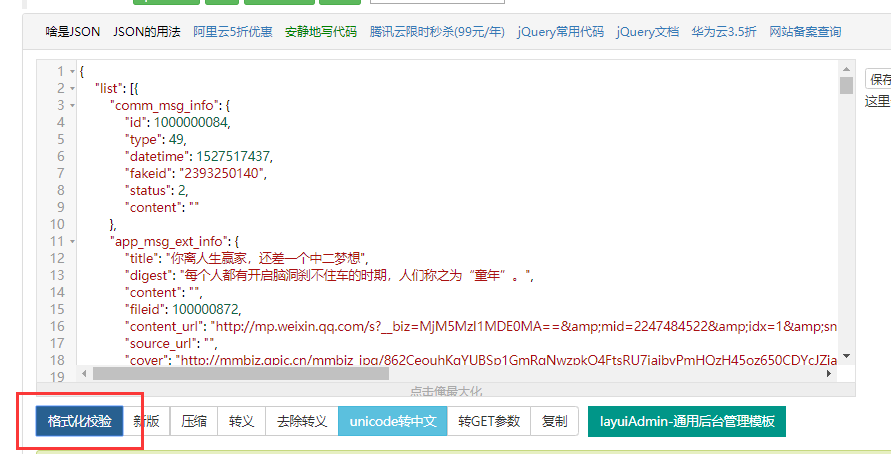
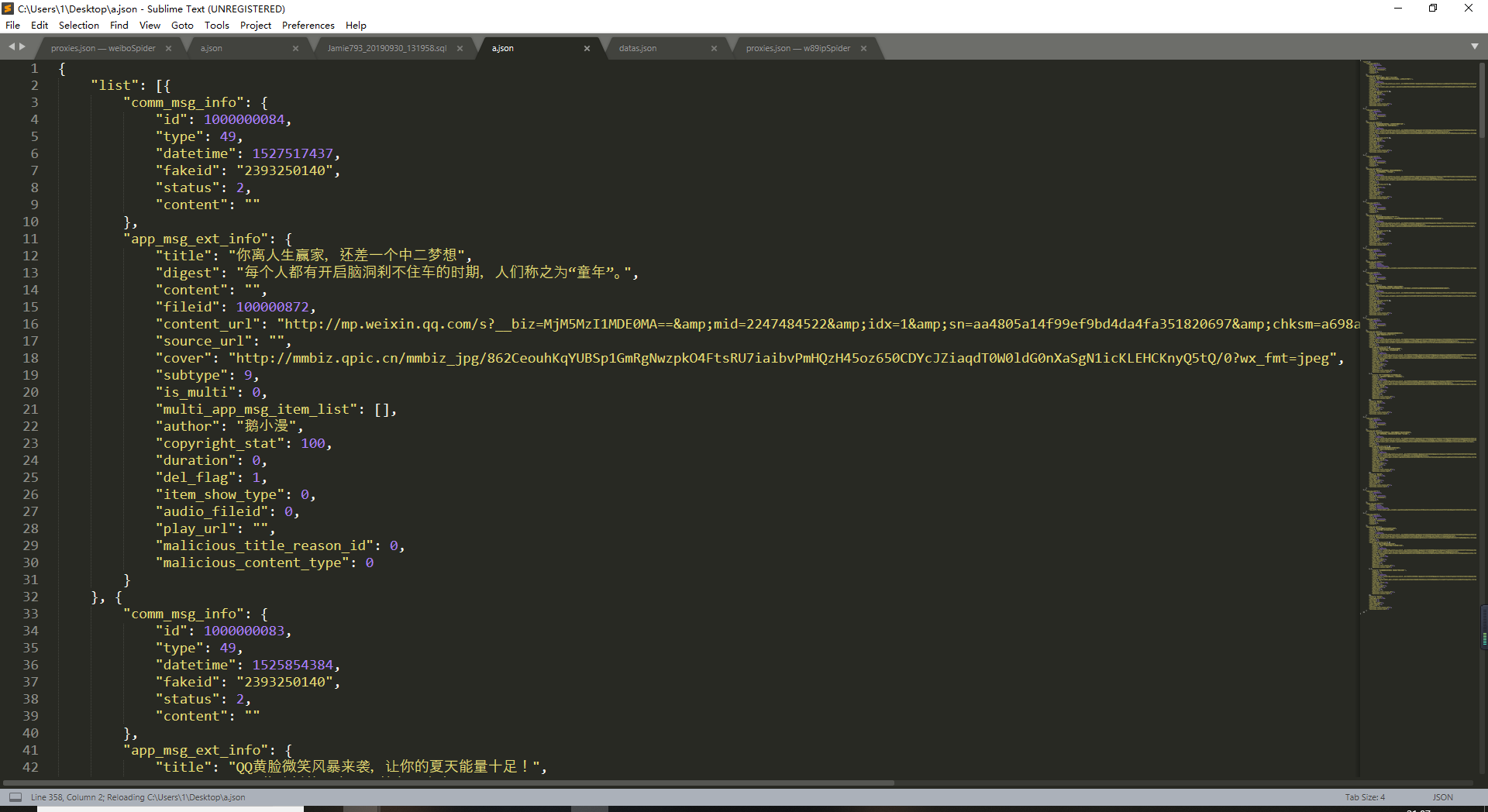
上图中可以看到datetime就是一个10位的时间戳
时间和数据是分开写的不过同一时间的数据和时间都是同一个分支中
而app_msg_ext_info就是我们要的数据title就是标题
content_url就是文章的链接
cover是我们在公众号历史页面看到的每一条数据右边的图片
multi_app_msg_item_list当数据在短暂时间发送很多条时会存在第一条数据中的这个节点中
数据到这里就分析的差不多了不过最重要是文章一中所获取的链接中的key是会过期的大概半小时左右要是爬虫报错提示找不到json节点就是key过期了需要重新获取
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Jamie793’ S Blog!
 wechat
wechat alipay
alipay
评论